[자료구조] 12.고급정렬
12장 고급 정렬
참고 - https://www.youtube.com/watch?v=tpWVyJqehG4 [얼굴인식 스노우 카메라 쉽게 따라만들기 - Python] 참고 - https://medium.com/analytics-vidhya/facial-expression-detection-using-machine-learning-in-python-c6a188ac765f [Facial expression detection using Machine Learning in Python] 참고 - https://machinelearningmastery.com/face-recognition-using-principal-component-analysis/ [Face Recognition using Principal Component Analysis] 참고 - A Comparative Study on Facial Recognition Algorithms [논문] 참고 - https://www.geeksforgeeks.org/cropping-faces-from-images-using-opencv-python/ [Cropping Faces from Images using OpenCV – Python] 참고 - https://medium.com/@jsflo.dev/training-a-tensorflow-model-to-recognize-emotions-a20c3bcd6468 [Training a TensorFlow model to recognize emotions] 참고 - https://bskyvision.com/entry/python-cv2imread-%ED%95%9C%EA%B8%80-%ED%8C%8C%EC%9D%BC-%EA%B2%BD%EB%A1%9C-%EC%9D%B8%EC%8B%9D%EC%9D%84-%EB%AA%BB%ED%95%98%EB%8A%94-%EB%AC%B8%EC%A0%9C-%ED%95%B4%EA%B2%B0-%EB%B0%A9%EB%B2%95 [cv2.imread 한글 경로 인식 문제 해결법]
[AIHub]
원본 데이터의 크기가 약 500기가되기에 ssd작업공간에서 작업하기 힘들것으로 파악되어 open cv를 활용하여 JPG파일을 JPEG 파일 형식으로 압축하였다. 이때 CNN 분석에서 JPEG Quality를 20으로 낮춰도 분류 모델에만 사용한다는 가정하에 문제없다는 논문을 읽어 Quality 40으로 압축 진행(데이터 크기가 거의 1/8사이즈로 줄었다)
import cv2
import os
import numpy as np
# upset: 당황, pleasure: 기쁨, anger: 분노, unrest: 불안, wound: 상처, sadness: 슬픔, neutrality: 중립
# 데이터 압축 함수
def convert_file(number,save_start, trial, feeling, filename):
for a in range(number):
if a is not 0:
img = "C:/Users/Administrator/Desktop/proj/Training/{}_TRAIN_{}/{} ({}).jpg".format(feeling, trial, filename, str(a+1))
print(img)
img_ori = cv2.imread(img)
img_name = "Training\\{}\\{} ({}).jpg".format(feeling, feeling, str(a+save_start))
cv2.imwrite(img_name, img_ori, [cv2.IMWRITE_JPEG_QUALITY, 40])
# 자동화를 위한 기초 포멧
save_start = 1
number = 0
# 각 폴더에 있는 사진개수 리스트
numbers = [9913,5727,11579,3873,11017,4757,7941,3727]
# 인코딩할 감정
feeling = "sadness"
save_start = save_start + number
number = numbers[0]
filename = "{}1".format(feeling)
trial = "01"
convert_file(number, save_start, trial, feeling, filename)
save_start = save_start + number
number = numbers[1]
filename = "{}2".format(feeling)
trial = "01"
convert_file(number, save_start, trial, feeling, filename)
save_start = save_start + number
number = numbers[2]
filename = "{}1".format(feeling)
trial = "02"
convert_file(number, save_start, trial, feeling, filename)
save_start = save_start + number
number = numbers[3]
filename = "{}2".format(feeling)
trial = "02"
convert_file(number, save_start, trial, feeling, filename)
save_start = save_start + number
number = numbers[4]
filename = "{}1".format(feeling)
trial = "03"
convert_file(number, save_start, trial, feeling, filename)
save_start = save_start + number
number = numbers[5]
filename = "{}2".format(feeling)
trial = "03"
convert_file(number, save_start, trial, feeling, filename)
save_start = save_start + number
number = numbers[6]
filename = "{}1".format(feeling)
trial = "04"
convert_file(number, save_start, trial, feeling, filename)
save_start = save_start + number
number = numbers[7]
filename = "{}2".format(feeling)
trial = "04"
convert_file(number, save_start, trial, feeling, filename)
감정 분석에 있어 노이즈 제거를 위해 데이터 크롭을 진행하였다. 머리카락, 옷, 악세서리, 배경등은 감정 분석에 큰 영향을 끼치지 않는다 판단하고 오로지 눈코입 얼굴 표정만으로 학습을 진행하기로 결정.
[참고] https://www.tutorialspoint.com/how-to-crop-and-save-the-detected-faces-in-opencv-python [How to crop and save the detected faces in OpenCV Python?]
import cv2
def crop_file(emotion, number):
for n in range(number):
route = 'Training\\{}\\{}1 ({}).jpg'.format(emotion, emotion, n+1)
img = cv2.imread(route)
print(route)
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
face_cascade = cv2.CascadeClassifier('haarcascade_frontalface_alt2.xml')
faces = face_cascade.detectMultiScale(gray, 1.2, 4)
for (x, y, w, h) in faces:
cv2.rectangle(img, (x, y), (x+w, y+h), (0, 0, 255), 2)
faces = gray[y:y + h, x:x + w]
#cv2.imshow("face",faces)
cv2.imwrite('crop\\{}\\{}{}.jpg'.format(emotion, emotion, n+1), faces)
crop_file("anger", 53591)
crop_file("neutrality", 57935)
crop_file("pleausre", 49198)
crop_file("sadness", 58526)
crop_file("unrest", 46495)
crop_file("upset", 47016)
crop_file("wound", 54992)
이때 이미지 크롭을 흑백 사진으로 진행하였는데 이유는 색의 유무에 따라 차원수가 달라지고 차원이 늘어나면 날수록 처리해야하는 데이터 양이 기하급수적으로 늘어나기에 흑백으로 진행하였다. (또한 감정에 있어 색은 특수한 경우를 제외하고는 (연극이나 영화의 연출) 분석에 큰 영향을 끼치지 않을꺼라 판단)

또한 크롭한 이미지 중에 위 그림처럼 얼굴을 제대로 추출하지 못한 사진들이 존재한다.

이렇게 크롭된 이미지인데 원본이 궁금하여 밑에 업로드하였다.
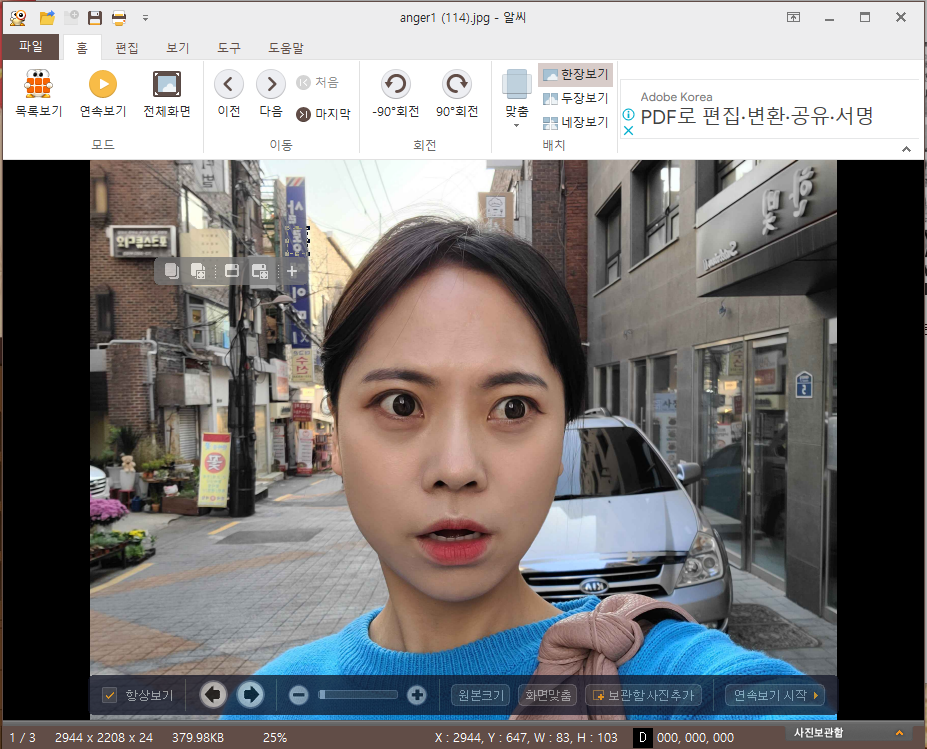
자세히 보면 잘못 크롭된 이미지에 눈코입의 윤곽선이 살짝 보이는것을 확인할 수 있다. 처음 opencv로 얼굴 위치를 인식할때 하나의 얼굴만이 아닌 복수의 얼굴좌표를 인식하게 한 다음 잘못 크롭된 이미지들만 삭제하는 방법이 있지만 데이터양이 이미 5만장을 넘어가고 대다수의 이미지가 제대로 크롭되는 것을 확인하였기에 진행하지 않았습니다.
import os
import shutil
import random
# n개의 숫자 중 2/3개의 데이터 추출 함수
def get_num(number):
sample = random.sample(range(1,number+1), round(number*2/3)-1)
return sample
def get_sample(emotion, number):
for num in get_num(number):
path = "data\\{}\\{} ({}).jpg".format(emotion, emotion, num)
path_to = "data\\Test\\{}\\{} ({}).jpg".format(emotion, emotion, num)
shutil.move(path, path_to)
if os.path.exists(path_to):
print("exists")
get_sample("anger", 2858)
get_sample("neutrality", 3077)
get_sample("pleasure", 2957)
get_sample("sadness", 2940)
get_sample("unrest", 3051)
get_sample("upset", 2926)
get_sample("wound", 2865)
255사이즈 흑백 얼굴데이터를 크롭한 후 전처리를 마쳤습니다. 베이스 라인 모델 생성 후 CNN을 활용하여 모델 성능 향상을 시도해보겠습니다.
[참고] https://medium.com/analytics-vidhya/facial-expression-detection-using-machine-learning-in-python-c6a188ac765f [Facial expression detection using Machine Learning in Python]
학습된 모델을 .json 파일로 저장했습니다.
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
import utils
import os
from tensorflow.keras.preprocessing.image import ImageDataGenerator
from tensorflow.keras.layers import Dense, Input, Dropout,Flatten, Conv2D
from tensorflow.keras.layers import BatchNormalization, Activation, MaxPooling2D
from tensorflow.keras.models import Model, Sequential
from tensorflow.keras.optimizers import Adam
from tensorflow.keras.callbacks import ModelCheckpoint, ReduceLROnPlateau
from tensorflow.keras.utils import plot_model
from IPython.display import SVG, Image
from livelossplot.inputs.tf_keras import PlotLossesCallback
import tensorflow as tf
# Train 폴더내의 각 감정 폴더안에 몇개의 이미지가 있는지 확인
for expression in os.listdir("data\\Train\\"):
print(str(len(os.listdir("data\\Train\\" + expression))) + " " + expression + " images")
img_size = 48
batch_size = 64
datagen_train = ImageDataGenerator(horizontal_flip=True)
train_generator = datagen_train.flow_from_directory("data\\Train\\",
target_size=(img_size,img_size),
color_mode="grayscale",
batch_size=batch_size,
class_mode='categorical',
shuffle=True)
datagen_validation = ImageDataGenerator(horizontal_flip=True)
validation_generator = datagen_validation.flow_from_directory("data\\Test\\",
target_size=(img_size,img_size),
color_mode="grayscale",
batch_size=batch_size,
class_mode='categorical',
shuffle=False)
# Initialising the CNN
model = Sequential()
# 1 - Convolution
model.add(Conv2D(64,(3,3), padding='same', input_shape=(48, 48,1)))
model.add(BatchNormalization())
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
# 2nd Convolution layer
model.add(Conv2D(128,(5,5), padding='same'))
model.add(BatchNormalization())
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
# 3rd Convolution layer
model.add(Conv2D(512,(3,3), padding='same'))
model.add(BatchNormalization())
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
# 4th Convolution layer
model.add(Conv2D(512,(3,3), padding='same'))
model.add(BatchNormalization())
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
# Flattening
model.add(Flatten())
# Fully connected layer 1st layer
model.add(Dense(256))
model.add(BatchNormalization())
model.add(Activation('relu'))
model.add(Dropout(0.25))
# Fully connected layer 2nd layer
model.add(Dense(512))
model.add(BatchNormalization())
model.add(Activation('relu'))
model.add(Dropout(0.25))
model.add(Dense(7, activation='softmax'))
opt = Adam(lr=0.0005)
model.compile(optimizer=opt, loss='categorical_crossentropy', metrics=['accuracy'])
model.summary()
plot_model(model, to_file='model.png', show_shapes=True, show_layer_names=True)
Image('model.png',width=400, height=200)
epochs = 15
steps_per_epoch = train_generator.n//train_generator.batch_size
validation_steps = validation_generator.n//validation_generator.batch_size
reduce_lr = ReduceLROnPlateau(monitor='val_loss', factor=0.1,
patience=2, min_lr=0.00001, mode='auto')
checkpoint = ModelCheckpoint("model_weights.h5", monitor='val_accuracy',
save_weights_only=True, mode='max', verbose=1)
callbacks = [PlotLossesCallback(), checkpoint, reduce_lr]
history = model.fit(
x=train_generator,
steps_per_epoch=steps_per_epoch,
epochs=epochs,
validation_data = validation_generator,
validation_steps = validation_steps,
callbacks=callbacks
)
model_json = model.to_json()
model.save_weights('model_weights.h5')
with open("model.json", "w") as json_file:
json_file.write(model_json)
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
import utils
import os
import tensorflow as tf
from tensorflow.keras.preprocessing.image import ImageDataGenerator
from tensorflow.keras.layers import Dense, Input, Dropout,Flatten, Conv2D
from tensorflow.keras.layers import BatchNormalization, Activation, MaxPooling2D
from tensorflow.keras.models import Model, Sequential
from tensorflow.keras.optimizers import Adam
from tensorflow.keras.callbacks import ModelCheckpoint, ReduceLROnPlateau
from tensorflow.keras.utils import plot_model
from tensorflow.keras.models import model_from_json
from IPython.display import SVG, Image
from livelossplot.inputs.tf_keras import PlotLossesCallback
class FacialExpressionModel(object):
EMOTIONS_LIST = ["anger", "neutrality", "pleasure", "sadness", "unrest", "upset", "wound"]
def __init__(self, model_json_file, model_weights_file):
# load model from JSON file
with open(model_json_file, "r") as json_file:
loaded_model_json = json_file.read()
self.loaded_model = model_from_json(loaded_model_json)
# load weights into the new model
self.loaded_model.load_weights(model_weights_file)
self.loaded_model.make_predict_function()
def predict_emotion(self, img):
self.preds = self.loaded_model.predict(img)
return FacialExpressionModel.EMOTIONS_LIST[np.argmax(self.preds)]
import cv2
facec = cv2.CascadeClassifier('haarcascade_frontalface_default.xml')
model = FacialExpressionModel("model.json", "model_weights.h5")
font = cv2.FONT_HERSHEY_SIMPLEX
class VideoCamera(object):
def __init__(self):
self.video = cv2.VideoCapture(0)
def __del__(self):
self.video.release()
# returns camera frames along with bounding boxes and predictions
def get_frame(self):
_, fr = self.video.read()
gray_fr = cv2.cvtColor(fr, cv2.COLOR_BGR2GRAY)
faces = facec.detectMultiScale(gray_fr, 1.3, 5)
for (x, y, w, h) in faces:
fc = gray_fr[y:y+h, x:x+w]
roi = cv2.resize(fc, (48, 48))
pred = model.predict_emotion(roi[np.newaxis, :, :, np.newaxis])
cv2.putText(fr, pred, (x, y), font, 1, (255, 255, 0), 2)
cv2.rectangle(fr,(x,y),(x+w,y+h),(255,0,0),2)
return fr
def gen(camera):
while True:
frame = camera.get_frame()
cv2.imshow('Facial Expression Recognization',frame)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
cv2.destroyAllWindows()
gen(VideoCamera())
12장 고급 정렬
Dijkstra 최단 경로 알고리즘
8장 트리
Abstract
선택 정렬 알고리즘
연결된 구조
큐에 대한 정의
스택의 개념과 동작 원리
1. 리스트 & 집합 & 배열
1. 파이썬 이란?
1. 교과서 정리
1. 자료구조와 알고리즘
논문 정리 논문 요약
[우분투] 파이썬 가상환경 만들고 사용하기
[우분투] 파이썬 가상환경 만들고 사용하기 - venv 사용하여 가상환경 생성
1. 개념
활동내용
활동내용
활동내용
- hhttps://dacon.io/competitions/official/236050/overview/description
활동내용
외국계 기업의 정확한 뜻
활동내용
1. 다항함수(Polynomial Function)
활동내용
출처: https://gaussian37.github.io/ml-sklearn-saving-model/
1. 경사도벡터(Gradient Vector)
[참고] - https://blog.est.ai/2020/03/%EB%94%A5%EB%9F%AC%EB%8B%9D-%EB%AA%A8%EB%8D%B8-%EC%95%95%EC%B6%95-%EB%B0%A9%EB%B2%95%EB%A1%A0%EA%B3%BC-bert-%EC%95%95%E...
- https://aihub.or.kr/aihubdata/data/view.do?currMenu=115&topMenu=100&aihubDataSe=realm&dataSetSn=631
머신러닝 스터디 팀4 활동 보고서
1. 영유아 행동인식을 통한 발달평가 XXX - https://aihub.or.kr/aihubdata/data/view.do?currMenu=115&topMenu=100&aihubDataSe=realm&dataSetSn=631
https://www.itworld.co.kr/insight/109825 [ITWorld - 머신러닝 라이브러리, 텐서플로우의 이해] https://tensorflow.blog/%EC%BC%80%EB%9D%BC%EC%8A%A4-%EB%94%A5%EB%9F%AC%EB%8B...
http://matrix.skku.ac.kr/math4ai-intro/W13/
랜덤(random) 모듈
1팀. 주식시세 차익 알림
차원축소와 매니폴드 학습
인공지능 기초 2022-2 Project Proposer
추천 알고리즘의 기본 협업 필터링(Collaborative Filtering) • Memory Based Approach User-based Filtering I...
자소서 지원동기 효과적인 작성법
분명히 로컬에서 삭제한 파일인데 원격에 반영되지 않는 경우가 있다. git status로 했을 때 삭제 됐다고 뜨는데 add를 해도 안먹고 commit을 해도 반영이 안되는 것이다…
1. 결정 트리
[공통] 마크다운 markdown 작성법
Git 설치 & 환경설정
첫 블로그 생성입니다. 앞으로 잘 부탁드려요.