[자료구조] 12.고급정렬
12장 고급 정렬
[참고] - https://blog.est.ai/2020/03/%EB%94%A5%EB%9F%AC%EB%8B%9D-%EB%AA%A8%EB%8D%B8-%EC%95%95%EC%B6%95-%EB%B0%A9%EB%B2%95%EB%A1%A0%EA%B3%BC-bert-%EC%95%95%EC%B6%95/
딥러닝(Deep Learning)은 뛰어난 성능과 높은 모델의 확장성(Scalability)으로 인해 많은 주목을 받았고, 요즘 산업계에서도 활발하게 적용되고 있습니다. 하지만 모델의 높은 확장성은 또 다른 문제를 불러오게 되었습니다.
기본적으로 딥러닝 모델의 성능은 그 크기에 비례하는 경향을 보입니다. 그렇다면 우리가 좋은 성능의 모델을 얻기 위해서는 계속해서 모델을 키우기만 하면 될까요? 딥러닝 모델이 커지면 어떤 문제점들이 있을까요? 작은 딥러닝 모델로도 큰 모델과 같은 성능을 얻을 수 있을까요?
이 글에서는 이러한 의문점을 연구하는 분야인 모델 압축(Model Compression)에 대해 이야기 해보려고 합니다. 특히, 현재 자연어처리(Natural Language Processing, NLP) 분야에서의 모델 발전 방향과 문제점, 모델 압축 방법론의 등장, 관련된 논문들을 다루려고 합니다.
딥러닝은 CNN(Convolutional Neural Network)이 2012년 ILSVRC(ImageNet Large-Scale Visual Recognition Challenge)에서 뛰어난 성능으로 우승을 하며, 큰 주목을 받았습니다. 그 이후로 컴퓨터 비전 분야에서는 VGGNet(2014), GoogLeNet(2015), ResNet(2015), DenseNet(2016) 등의 다양한 네트워크 아키텍처가 등장하여 모델을 점점 깊고 크게 만들어 나갔고, 이러한 거대한 모델을 거대한 이미지 데이터셋을 이용하여 미리 학습(Pre-train)시키고, 이를 특정 응용 분야에 맞춰 새로 학습(Fine-tune)하는 방식의 접근법이 주류가 되었습니다.
반면, 자연어 처리(NLP) 분야의 초기 딥러닝 연구 방향은 비전 분야와는 약간 달랐습니다. 자연어 처리에서는 ‘RNN(Recurrent Neural Network)’이라고 하는 연속된 데이터를 다루는데 특화된 모델을 주로 사용하였습니다. RNN은 모델이 처리해야 하는 데이터가 길어짐에 따라 기울기(Gradient)가 사라진다는 문제와 다음 입력 데이터 처리를 위해 이전 데이터가 필요하여 병렬화가 어렵다는 문제가 있었습니다. RNN 모델이 가진 한계로 인해, 자연어 처리에서는 컴퓨터 비전에서만큼 모델을 거대화하기 어려웠습니다.
또한, 컴퓨터 비전에서는 ImageNet에서 분류 학습을 한 모델이 다른 분야에서도 필요한 특징을 잘 뽑아내었는데요. 자연어 처리에서는 이에 대응되는 거대한 데이터셋과 다른 분야에서 특징을 잘 뽑아내기 위한 사전 학습 방법이 잘 알려져 있지 않아, 이미 학습된 모델이 다른 분야에 활용되기 어려웠습니다. 자연어 처리 분야에서 사전 학습을 위한 주된 접근법은 거대한 말뭉치(Corpus)에서 단어 임베딩(Word embedding)을 학습하여 재사용하는 정도였습니다.
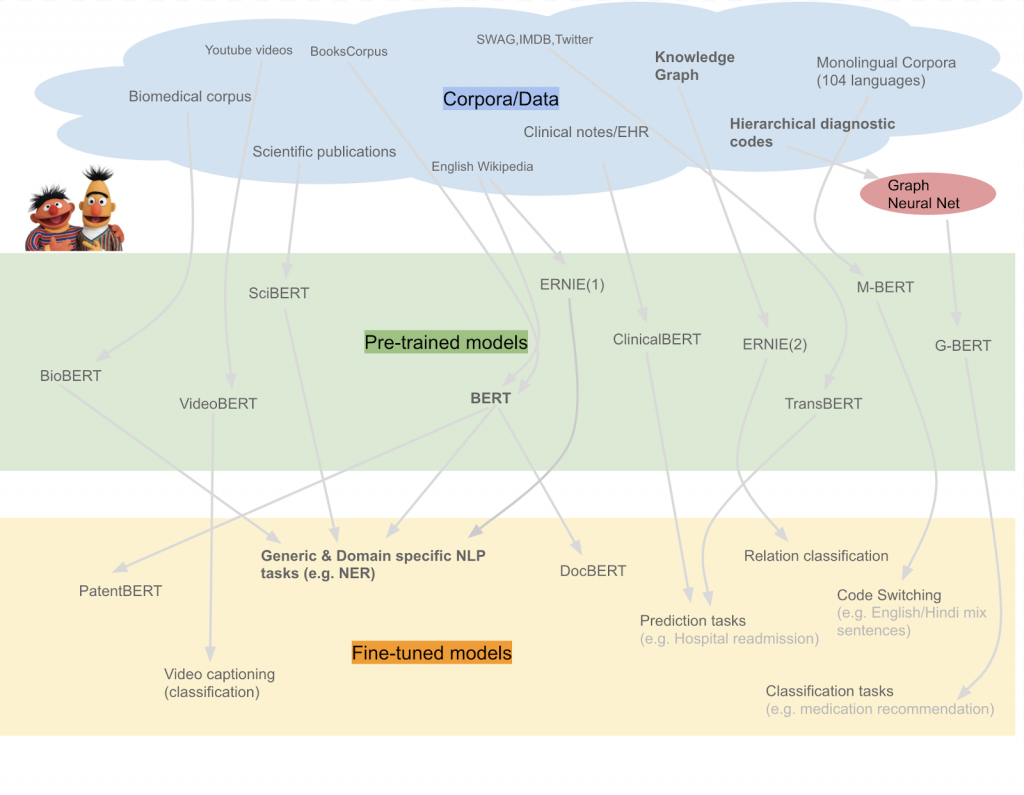
하지만 2018년에 Google이 BERT(Bidirectional Encoder Representations from Transformers)를 발표하며, 자연어 처리 분야에서도 거대한 모델들이 속속 등장하기 시작하였습니다. BERT는 Transformer 기반의 모델로, 자연어 처리에서도 컴퓨터 비전과 마찬가지로 거대한 모델의 사전 학습 - 재학습이 가능해졌고, 다양한 문제들에서 뛰어난 성능을 보여주었습니다.
이후 다양한 형태의 바리에이션이 나오면서 BERT는 현재 NLP 연구의 주류가 되었습니다. 현재 NLP 연구는 거대한 모델을 만들고, 많은 데이터를 이용해 모델을 미리 학습한 후 응용 분야에 맞춰 재학습하는 접근 방식을 취하고 있습니다.
딥러닝을 이용해 해결하려는 문제가 복잡해지면서 요구되는 모델의 크기가 급격하게 증가하게 되었고, 이에 따라 다양한 문제점들이 등장하기 시작했습니다.
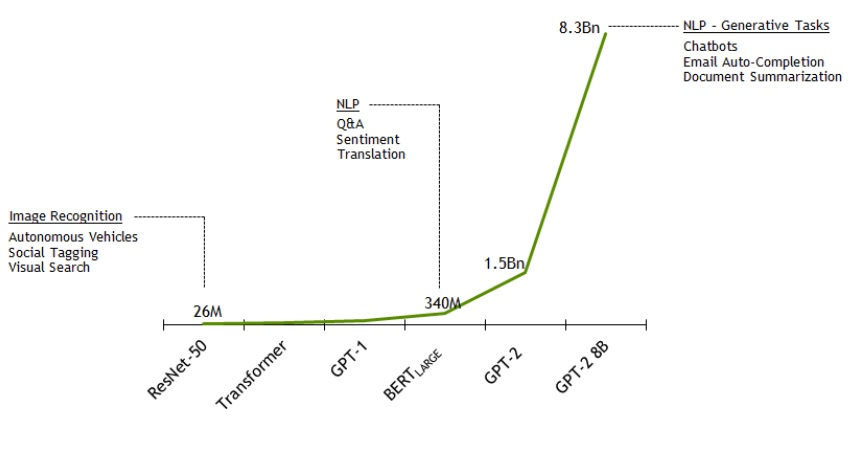
Memory Limitation
Training/Inference Speed
Worse Performance
Practical problems
12장 고급 정렬
Dijkstra 최단 경로 알고리즘
8장 트리
Abstract
선택 정렬 알고리즘
연결된 구조
큐에 대한 정의
스택의 개념과 동작 원리
1. 리스트 & 집합 & 배열
1. 파이썬 이란?
1. 교과서 정리
1. 자료구조와 알고리즘
논문 정리 논문 요약
[우분투] 파이썬 가상환경 만들고 사용하기
[우분투] 파이썬 가상환경 만들고 사용하기 - venv 사용하여 가상환경 생성
1. 개념
활동내용
활동내용
활동내용
- hhttps://dacon.io/competitions/official/236050/overview/description
활동내용
외국계 기업의 정확한 뜻
활동내용
1. 다항함수(Polynomial Function)
활동내용
출처: https://gaussian37.github.io/ml-sklearn-saving-model/
1. 경사도벡터(Gradient Vector)
[참고] - https://blog.est.ai/2020/03/%EB%94%A5%EB%9F%AC%EB%8B%9D-%EB%AA%A8%EB%8D%B8-%EC%95%95%EC%B6%95-%EB%B0%A9%EB%B2%95%EB%A1%A0%EA%B3%BC-bert-%EC%95%95%E...
- https://aihub.or.kr/aihubdata/data/view.do?currMenu=115&topMenu=100&aihubDataSe=realm&dataSetSn=631
머신러닝 스터디 팀4 활동 보고서
1. 영유아 행동인식을 통한 발달평가 XXX - https://aihub.or.kr/aihubdata/data/view.do?currMenu=115&topMenu=100&aihubDataSe=realm&dataSetSn=631
https://www.itworld.co.kr/insight/109825 [ITWorld - 머신러닝 라이브러리, 텐서플로우의 이해] https://tensorflow.blog/%EC%BC%80%EB%9D%BC%EC%8A%A4-%EB%94%A5%EB%9F%AC%EB%8B...
http://matrix.skku.ac.kr/math4ai-intro/W13/
랜덤(random) 모듈
1팀. 주식시세 차익 알림
차원축소와 매니폴드 학습
인공지능 기초 2022-2 Project Proposer
추천 알고리즘의 기본 협업 필터링(Collaborative Filtering) • Memory Based Approach User-based Filtering I...
자소서 지원동기 효과적인 작성법
분명히 로컬에서 삭제한 파일인데 원격에 반영되지 않는 경우가 있다. git status로 했을 때 삭제 됐다고 뜨는데 add를 해도 안먹고 commit을 해도 반영이 안되는 것이다…
1. 결정 트리
[공통] 마크다운 markdown 작성법
Git 설치 & 환경설정
첫 블로그 생성입니다. 앞으로 잘 부탁드려요.